Hàm Sigmoid là một khái niệm phổ biến trong Deep Learning. Bài viết sẽ giới thiệu về Hàm Sigmoid và những thông tin về lịch sử hình thành của nó.
Hàm Sigmoid là gì?
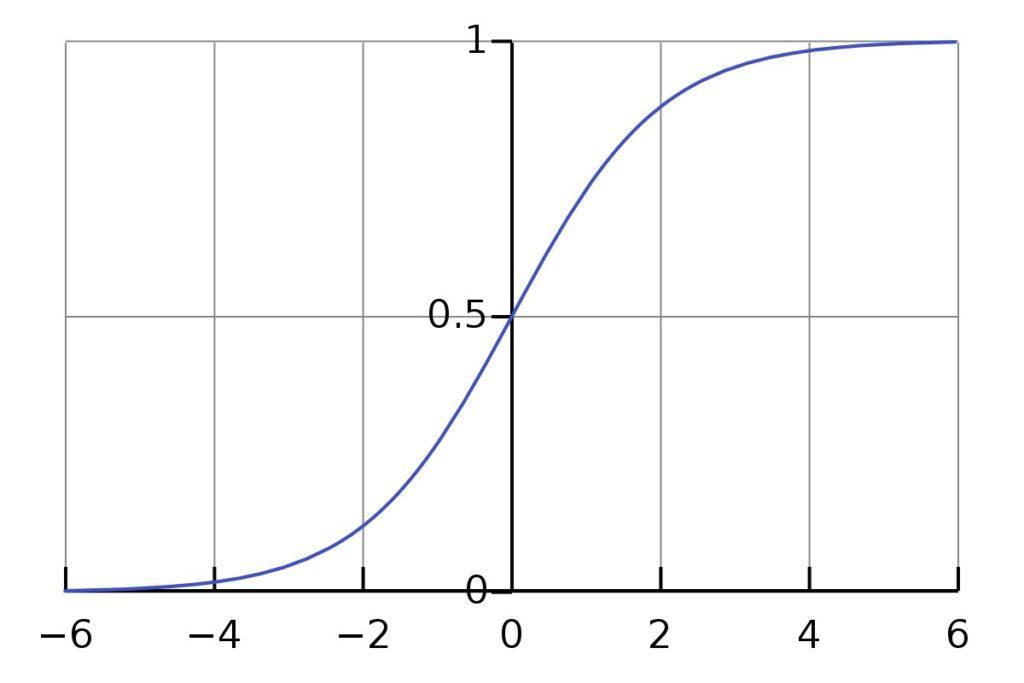
Hàm Sigmoid, còn được gọi là đường cong Sigmoid, là một hàm toán học được biểu diễn dưới dạng hình chữ S. Hàm này thể hiện sự biến đổi của các giá trị trong khoảng từ 0 đến 1. Hàm Sigmoid là một trong những hàm kích hoạt phi tuyến được sử dụng phổ biến nhất.
Có nhiều dạng hàm Sigmoid phổ biến như hàm Sigmoid logistic, hàm tiếp tuyến hyperbol và hàm ArcTan. Trong lĩnh vực học máy, thuật ngữ Hàm Sigmoid thường được sử dụng để chỉ hàm Sigmoid logistic, còn được gọi là hàm logistic.
Hàm Sigmoid được sử dụng cho mục đích gì?
Tất cả các dạng hàm Sigmoid đều có một đặc điểm chung. Chúng có khả năng ánh xạ các giá trị đầu vào vào một phạm vi nhất định. Cụ thể, đầu vào sẽ được ánh xạ từ 0 đến 1 hoặc -1 đến 1. Vì vậy, Hàm Sigmoid được sử dụng để biến đổi giá trị số thành một giá trị xác suất.
Hàm Sigmoid nhận giá trị đầu vào và thực hiện các công việc sau:
- Nếu giá trị đầu vào là âm, Hàm Sigmoid ánh xạ gần như tất cả giá trị về 0.
- Đối với hầu hết các giá trị đầu vào dương, Hàm Sigmoid ánh xạ giá trị đó gần đến 1.
- Trong trường hợp giá trị đầu vào gần 0, Hàm Sigmoid ánh xạ nó thành giá trị từ 0 đến 1.
Lịch sử của Hàm Sigmoid
Khái niệm Hàm Sigmoid không phải là mới, nó đã tồn tại từ lâu. Lịch sử của Hàm Sigmoid có thể được chia thành hai giai đoạn như sau:
Hàm Sigmoid trước năm 1975
Năm 1798, Thomas Robert Malthus đã xuất bản cuốn sách “An Essay on the Principle of Population” (Một bài luận về Nguyên tắc Dân số). Ông là một giáo sĩ và nhà kinh tế người Anh. Trong cuốn sách này, ông khẳng định rằng dân số tăng theo một tiến trình hình học. Ông cho rằng mỗi 25 năm, dân số sẽ tăng gấp đôi. Trong khi đó, nguồn lương thực tăng theo cấp số nhân. Ông cho rằng sự khác biệt giữa hai con số này chính là sự lan rộng của hiện tượng đói khát.
Vào cuối những năm 1830, nhà toán học người Bỉ Pierre François Verhulst đã nghiên cứu các phương pháp để mô hình hóa sự tăng trưởng dân số. Verhulst nhấn mạnh rằng dân số không tăng theo cấp số nhân mãi mãi, mà nó sẽ đạt đến một giới hạn. Ông đã chọn Hàm logistic để mô hình hóa sự chậm lại của tốc độ tăng trưởng dân số.
Hàm Sigmoid tiếp tục được sử dụng trong các thế kỷ tiếp theo. Nhiều nhà sinh học và nhà khoa học khác sử dụng nó như một công cụ tiêu chuẩn để mô hình hóa sự tăng trưởng dân số.
Hàm Sigmoid sau năm 1975
Năm 1943, Warren McCulloch và Walter Pitts đã phát triển mô hình mạng thần kinh nhân tạo sử dụng ngưỡng cứng như một hàm kích hoạt. Theo đó, thần kinh sẽ đưa ra đầu ra là 1 hoặc 0 tùy thuộc vào giá trị đầu vào so với ngưỡng.

Năm 1972, Hugh Wilson và Jack Cowan đã nghiên cứu quá trình hoạt động của các tế bào thần kinh bằng cách sử dụng các phép toán. Họ sử dụng Hàm Sigmoid logistic để mô hình hóa quá trình kích hoạt của một tế bào thần kinh. Theo đó, nếu tế bào nhận được tín hiệu vượt qua ngưỡng kích hoạt, nó sẽ gửi tín hiệu đến các tế bào thần kinh khác. Mô hình này được gọi là mô hình Wilson – Cowan.
Từ những năm 1970 và 1980 trở đi, một số nhà nghiên cứu đã bắt đầu sử dụng các hàm Sigmoid trong các công thức của mạng thần kinh nhân tạo, lấy cảm hứng từ các mạng thần kinh sinh học. Năm 1998, Yann LeCun đã sử dụng Hàm tiếp tuyến hyperbol làm hàm kích hoạt trong mạng LeNet nổi tiếng của mình. Đây là mạng đầu tiên có thể nhận dạng các chữ số viết tay với mức độ chính xác thực tế.
Trong những năm gần đây, các mạng thần kinh nhân tạo đã chuyển từ sử dụng Hàm Sigmoid sang sử dụng Hàm ReLU. Lý do của điều này là tất cả các biến thể của Hàm Sigmoid đã được thiết kế cho mục đích tính toán. Trong khi đó, Hàm ReLU có tính chất phi tuyến cần thiết để khai thác tốt hiệu suất của mạng thần kinh. Hàm ReLU cũng thực hiện tính toán nhanh chóng.
Tóm lại, Hàm Sigmoid đã có một quá trình hình thành và phát triển từ lâu. Qua bài viết này, hy vọng bạn đã hiểu thêm về Hàm Sigmoid.
Got It Vietnam – Tham khảo: DeepAI.org






{kind=link}